| Table of contents |
In this example, an integral equation is to be solved by representing the discretised operator with an 𝓗-matrix, whereby the 𝓗-matrix is constructed using a matrix coefficient function for entries of the equation system. Furthermore, for the iterative solver a preconditioner is computed using 𝓗-LU factorisation.
Problem Description
Given the integral equation
![\[ \int_0^1 \log|x-y| \mathbf{u}(y) dy = \mathbf{f}(x), \quad x \in [0,1] \]](form_155.png)
with ![$\mathbf{u} : [0,1] \to \mathbf{R}$](form_145.png) being sought for a given right hand side
being sought for a given right hand side ![$\mathbf{f} : [0,1] \to \mathbf{R}$](form_146.png) , the Galerkin discretisation with constant ansatz functions
, the Galerkin discretisation with constant ansatz functions 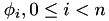
![\[ \phi_i(x) = \left\{ \begin{array}{ll} 1, & x \in \left[\frac{i}{n},\frac{i+1}{n} \right] \\ 0, & \mathrm{otherwise} \end{array} \right. \]](form_148.png)
leads to a linear equation system 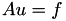 where
where 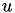 contains the coefficients of the discretised
contains the coefficients of the discretised 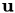 and
and 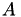 is defined by
is defined by
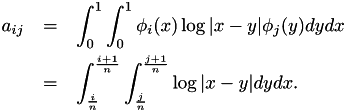
The right hand side  is given by
is given by
![\[ f_i = \int_0^1 \phi_i(x) f(x) dx. \]](form_151.png)
- Remarks
- This example is identical to the introductory example in [BoerGraHac:2003b]}.
Coordinates and Cluster Trees
The code starts with the standard initialisation:
Together with the initialisation, the verbosity level of HLIBpro was increased to have additional output during execution. The corresponding function set_verbosity is available in the namespace HLIB::CFG.
For clustering the unknowns, coordinate information is to be defined. For this 1d example, the indices are placed in the middle of equally sized intervals.
Coordinates in HLIBpro are vectors of the corresponding dimension, e.g. one in for this problem. The set of all coordinates is stored in objects of type TCoordinate.
The usage of smart pointers, e.g. unique_ptr, is advised, and extensively used in HLIBpro, since it decreases the possibility of memory leaks by automatically deleting the objects upon destruction of the spart pointer variable, e.g. when leaving the local block.
Having coordinates for each index, the cluster tree and block cluster tree can be constructed.
For the cluster tree, the partitioning strategy for the indices is determined automatically by TAutoBSPPartStrat. Furthermore, a  of size 20 is used during construction.
of size 20 is used during construction.
For the block cluster tree, the standard admissibility condition (see {eqn:std_adm}) implemented in TStdGeomAdmCond is used with 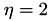 .
.
Matrix Construction and Coefficient Function
Using the block cluster tree, finally the 𝓗-matrix can be constructed. For this, adaptive cross approximation (ACA, see ???) is applied to compute low rank approximations of admissibly matrix blocks. In HLIBpro, an improved version of ACA is implemented in TACAPlus.
ACA only needs access to the matrix coefficients of the dense matrix. Those are provided by TLogCoeffFn, which will be discussed below. Finally, the block wise accuracy of the 𝓗-matrix approximation has to be defined using TTruncAcc objects. In this case, an accuracy of 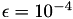 is used.
is used.
- Remarks
- Matrix construction is an example of a parallel algorithm in 𝓗𝖫𝖨𝖡𝗉𝗋𝗈. On shared memory machines, e.g. standard PCs or compute servers, by default as many threads as there are processor cores in the system are used by 𝓗𝖫𝖨𝖡𝗉𝗋𝗈. The can be changed by using
CFG::set_nthreads().
The coefficient function used during matrix construction is implemented in class TLogCoeffFn.
It is derived from TPermCoeffFn, where the interface is defined for coefficient evaluation with permuted indices. The reordering is necessary, since due to the construction of the cluster tree the numbering of the indices in the 𝓗-matrix is usually different from the corresponding numbering in the application. The latter is referred to as the external numbering, whereas the first is called the internal numbering.
Going on with TLogCoeffFn, the step width for the grid is stored as an internal variable for kernel evaluation:
In the constructor, the permutation for mapping the internal to the external numbering are provided, both for rows and for columns, together with the step width:
The actual interface for the evaluation of the matrix coefficients is implemented by the function eval, which is defined in TPermCoeffFn and has to be overloaded:
This functions gets a set of indices for rows (rowidxs) and columns (colidxs) and a pointer to a memory block, where all the coefficients should be stored. The indices in both sets are already in the external numbering, hence the indices can directly be used for kernel evaluation. The mapping was performed by TPermCoeffFn. The memory layout of matrix is column wise, which holds for almost all data in HLIBpro. This is due to the memory layout of BLAS/LAPACK, originally implemented in Fortran, which uses column wise storage.
TPermCoeffFn is derived from TCoeffFn, which uses a slightly different evaluation interface based on index sets in the internal numbering. TPermCoeffFn overloads this method with the conversion between both numberings and implements the new eval method. To avoid compiler warnings about ``hidden functions'', the first version is brought into local scope by
By default, the format of the final matrix defined by the coefficients will be unsymmetric, e.g. lower and upper half of the matrix will be built. Please note, that this will not effect the actual algebraic matrix which may still be symmetric or hermtitian. Only the storage and subsequent algorithms are affected in terms of computational costs.
To change the matrix format, the function matrix_format has to be overloaded. In this case, as the matrix is symmetric, this looks like
Finally, TLogCoeffFn has to signal the value type, e.g. real or complex valued, to the matrix construction object with the method is_complex.
It should be noted, that for a complex coefficient function, to evaluation method is not called eval but ceval.
𝓗-LU Factorisation
Having constructed the 𝓗-matrix, the corresponding equation system shall be solved. In most cases, a standard iterative solver will not be sufficient, e.g. either the convergence rate is to bad or there is no convergence at all. Therefore, a (good) preconditioner is needed, with the inverse of being the best possible. Since iterative schemes only need matrix-vector multiplication, the corresponding functionality for the inverse is sufficient. This is provided by an (𝓗-) LU factorisation of , or for the symmetric case, a LDL factorisation.
For this, either the factorisation classes may be used directly or, instead, the function factorise_inv be empoyed, which chooses uses a LU factorisation for unsymmetric matrices and a LDL factorisation otherwise. The return value is an object providing the functionality of a linear operator, e.g. evaluation of vectors. In this case, it corresponds to an operator for the evaluation of the inverse.
The copy of A is neccessary, since the matrix is modified during the factorisation. The accuracy is chosen to be the same as during matrix construction.
Iterative Solvers
Still missing is the right hand side of the equation system. In this example, it was chosen, such that 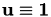 :
:
with rhs defined by
The RHS was built using the original ordering of the unknowns. To be used with 𝓗-arithmetic, it has to be reordered according to the internal numbering of the 𝓗-matrix as defined by the clustering process. The object for the cluster tree stores both kind of permutations, i.e., from external to internal (𝓗) numbering and from internal to external numbering. To reorder the RHS, the external to internal (e2i) permutation is used:
- Remarks
- 𝓗-matrices also store the mappings between internal and external numbering for the row and column index sets.
For the iterative solver TAutoSolver is used, which automatically chooses a suitable solver for the given combination of matrix and preconditioner. Furthermore, statistics about the solution process is stored in an object of type TSolver::TInfo, e.g. convergence rate, number of steps.
To check the accuracy of the computed solution, we compare it with the known exact solution. However, the exact solution uses external ordering, while the computed solution is still based on the internal ordering of the 𝓗-matrix. To compare both, the ordering has to be equal:
- Remarks
- Since the solution vector in this example is constant one, applying a permutation is redundant. However, in other examples, this would be important and was therefore also applied here.
The standard finalisation and catch block finishes the example:
