| Table of contents |
- Remarks
- This example corresponds to the C++ example "Solving an Integral Equation".
In this example, an integral equation is to be solved by representing the discretised operator with an 𝓗-matrix, whereby the 𝓗-matrix is constructed using a matrix coefficient function for entries of the equation system. Furthermore, for the iterative solver a preconditioner is computed using 𝓗-LU factorisation.
Problem Description
Given the integral equation
![\begin{displaymath} \int_0^1 \log|x-y| \mathbf{u}(y) dy = \mathbf{f}(x), \quad x \in [0,1] \end{displaymath}](form_139.png)
with ![$\mathbf{u} : [0,1] \to \mathbf{R}$](form_140.png) being sought for a given right hand side
being sought for a given right hand side ![$\mathbf{f} : [0,1] \to \mathbf{R}$](form_141.png) , the Galerkin discretisation with constant ansatz functions
, the Galerkin discretisation with constant ansatz functions 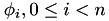
![\[ \phi_i(x) = \left\{ \begin{array}{ll} 1, & x \in \left[\frac{i}{n},\frac{i+1}{n} \right] \\ 0, & \mathrm{otherwise} \end{array} \right. \]](form_143.png)
leads to a linear equation system 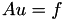 where
where 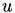 contains the coefficients of the discretised
contains the coefficients of the discretised 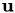 and
and 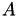 is defined by
is defined by
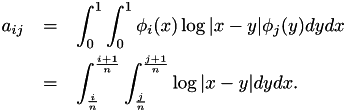
The right hand side 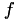 is given by
is given by
![\[ f_i = \int_0^1 \phi_i(x) f(x) dx. \]](form_146.png)
- Remarks
- This example is identical to the introductory example in [BoerGraHac:2003b]}.
Coordinates and Cluster Trees
The code starts with the standard initialisation:
Together with the initialisation, the verbosity level of HLIBpro was increased to have additional output during execution. The macro CHECK_INFO is defined as
and tests the result of a 𝓗𝖫𝖨𝖡𝗉𝗋𝗈 function call. If an error occured, the description of this error is queried using hlib_error_desc and printed to the screen.
For clustering the unknowns, coordinate information is to be defined. For this 1d example, the indices are placed in the middle of equally sized intervals.
Coordinates in HLIBpro are vectors of the corresponding dimension, e.g. one in for this problem.
Having coordinates for each index, the cluster tree and block cluster tree can be constructed.
For the cluster tree, the partitioning strategy for the indices is determined automatically by choosing HLIB_BSP_AUTO. For the block cluster tree, the standard admissibility condition (see {eqn:std_adm}) is used as defined by HLIB_ADM_STD_MIN with 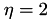 .
.
Matrix Construction and Coefficient Function
Using the block cluster tree, finally the 𝓗-matrix can be constructed. For this, adaptive cross approximation (ACA, see ???) is applied to compute low rank approximations of admissibly matrix blocks. In HLIBpro, an improved version of ACA, ACA+ is implemented.
ACA only needs access to the matrix coefficients of the dense matrix. Those are provided by a coefficient function kernel with an optional parameter h, which will be discussed below. Furthermore, the block wise accuracy of the 𝓗-matrix approximation has to be defined. In this case, an accuracy of 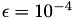 is used and stored in
is used and stored in acc. Finally, a flag indicates, whether the matrix is symmetric or not.
The coefficient function used during matrix construction comes in the form of a callback function:
It is called, whenever matrix coefficients are needed. Usually, a complete block of coefficients is requested by the internal matrix constructor, e.g. a full dense block in case of an inadmissible leaf or a full row/column in case of ACA. The row (column) indices for the requested coefficients are stored in rowidx (colidx) and are of size n (m). In the array matrix the coefficients have to be stored in column-wise order, e.g. the coefficient with the i'th row index and the j'th column index at position (i,j) or at matrix[j*n+i]. The final argument arg is the additional parameter to hlib_matrix_build_coeff at can be used to provided necessary data for the coefficient function. Here, it is the stepwidth 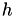 of the problem.
of the problem.
For a complex coefficient functions the callback function is identical except the value type of matrix, which is of type hlib_complex_t.
H-LU Factorisation
Having constructed the 𝓗-matrix, the corresponding equation system shall be solved. In most cases, a standard iterative solve will not be sufficient, e.g. either the convergence rate is to bad or there is no convergence at all. Therefore, a (good) preconditioner is needed, with the inverse of 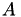 being the best possible. Since iterative schemes, only need matrix-vector multiplication, the corresponding functionality for the inverse is sufficient. This is provided by an (𝓗-) LU factorisation of , or for the symmetric case, a LDL factorisation:
being the best possible. Since iterative schemes, only need matrix-vector multiplication, the corresponding functionality for the inverse is sufficient. This is provided by an (𝓗-) LU factorisation of , or for the symmetric case, a LDL factorisation:
Since A is modified during the factorisation, a copy B is constructed. For the factorisation the accuracy is chosen to be equal as during matrix construction. The result of the factorisation is linear operator represented by the type hlib_linearoperator_t, which can be used to perform matrix vector multiplication. In this case, the evaluation of the inverse of is provided.
- Remarks
- A matrix can always be used as a linear operator, but not the other way around, i.e. a linear operator is not a full matrix object.
Iterative Solvers
Still missing is the right hand side of the equation system. In this example, it was chosen, such that 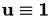 :
:
Here, hlib_vector_import copies the coefficients from b_arr to b and rhs is defined by
- Remarks
- Instead of using a special array
b_arr, the coefficients ofbcould directly be set usinghlib_vector_entry_set.
For the iterative solver the special auto solver is used, which automatically chooses a suitable solver for the given combination of matrix and preconditioner. Furthermore, statistics about the solution process is stored in solve_info, e.g. convergence rate, number of steps.
- Remarks
- Solvers in 𝓗𝖫𝖨𝖡𝗉𝗋𝗈 are based only on matrix vector multiplication and hence, only need the functionality of linear operators. This is an example, where matrices can simply be casted to the
hlib_linearoperator_ttype.
To check the accuracy of the computed solution, we compare it with the known exact solution:
Finally, all resources have to be freed and 𝓗𝖫𝖨𝖡𝗉𝗋𝗈 be finished:
- Remarks
- Please note, that the linear operator
A_invand the copyBofAare explicitly freed. By default,A_invwill only use the provided matrix object and does not perform memory management, e.g. deletion.
