Table of Contents
While the technical details of solving and preconditioning are discussed in Solvers, this section should comment on the practical issues related to the various preconditioners.
- Attention
- The discussion of the numerical tests below only applies to the equation system used in this example. The results, especially for classical preconditioners may vary strongly for other matrices. This example should therefore only be considered as a hint, that different preconditioners are available and may be tested for a specific problem to obtain optimal results.
Problem Setup
As a benchmark, we will use the same problem as in the Boundary Element Methods example, i.e., the Helmholtz SLP operator on the unit sphere. The wavenumber 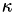 was chosen to be 16.
was chosen to be 16.
The source code for setting up the matrix and RHS is identical to the Boundary Element Methods example.
For this specific test, we use a grid with 62.466 vertices and 124.928 triangles. With a constant ansatz, this results in an ℋ-matrix of dimension 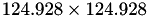 .
.
Furthermore, the matrix was built unsymmetric, i.e., both lower and upper triangular part are constructed, to prevent algorithmic properties of symmetric matrices, e.g., during matrix-vector solves, to influence the numerical results.
For comparison with the timings below, we need the time to build the ℋ-matrix, which is 75.9 seconds for a block-wise accuracy of 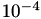 with ACA+.
with ACA+.
All tests below are performed using a single Intel Xeon E7-8857 CPU with 12 cores and 3GHz.
- Remarks
- Although the example uses a dense matrix, for sparse matrices similar tests may be done. However, note that point-wise versions of the various preconditioners, e.g., Jacobi, Gauss-Seidel, SOR or also ILU, do not need ℋ-arithmetic or 𝖧𝖫𝖨𝖡𝗉𝗋𝗈. Furthermore, several direct solvers are available, e.g., UMFPACK, PARDISO or MUMPS, which are very fast if they are applicable to a equation system.
No Preconditioner
First, the various solvers in 𝖧𝖫𝖨𝖡𝗉𝗋𝗈 should try to solve the system without any preconditioner. The stop criterion is chosen with a maximal number of 1000 steps and a reduction of the residual norm of 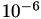 compared to the initial residual norm. Furthermore, the lower bound for the absolute residual norm was set to :
compared to the initial residual norm. Furthermore, the lower bound for the absolute residual norm was set to :
The results are
The fastest solver is TFQMR, which managed to reach the wanted residual norm within 575 steps. However, it needed 58.12 seconds to do so, which is almost as long as for building the matrix.
- Remarks
- In the following, only results for solvers are printed, which managed to converge within the given iteration limits.
Jacobi Preconditioner
The next test will use the Jacobi preconditioner, first the point-wise version:
The results now look as
The GMRES solver now is able to reduce the residual within 193 steps in 22.97 seconds. Also improved are the convergence rates of BiCGStab and TFQMR. CGS now is not able to converge, resulting in absent data.
However, point-wise Jacobi only uses the diagonal entries of 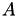 as an approximation. In the next test, the diagonal blocks of are used instead:
as an approximation. In the next test, the diagonal blocks of are used instead:
The third argument to the TJacobi constructor defines the block size and since no block smaller than diagonal blocks are supported by 𝖧𝖫𝖨𝖡𝗉𝗋𝗈, a 2 results in using all diagonal blocks for a block-wise Jacobi preconditioner.
Instead of a blocksize value of 2, one could also use 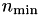 if known, since this is equivalent as it defines the size of the smallest diagonal blocks.
if known, since this is equivalent as it defines the size of the smallest diagonal blocks.
The results are:
The convergence rate actually decreases for GMRES and BiCGStab. Only TFQMR benefits a little.
The reason for this behaviour is, that although going from point-wise diagonal to block-diagonal with blocksize will increase the number of coefficients in the preconditioner, but the change in the overall approximation of 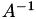 is still small, and hence the quality of the preconditioner does not change enbough to guarantee a better convergence for this example.
is still small, and hence the quality of the preconditioner does not change enbough to guarantee a better convergence for this example.
To improve this, we increase the diagonal blocksize to 100:
which gives the following results:
For comparison, also a blocksize of 500 is used:
Since the approximation to and hence also to is getter better with an increased blocksize, the convergence rates are also decreasing.
However, an increased block size also has drawbacks:
- The time for matrix-vector multiplication with the preconditioner is bigger.
- The setup time for the preconditioner increases, i.e., the time for inverting the diagonal blocks.
The increased time for matrix-vector multiplications can be seen for the BiCGStab and the TFQMR solver, which have similar solve times for both block sizes, although the number of iteration steps is reduced.
For point-wise Jacobi and for a block-size equal to , the setup was actually negligible. So lets correct the above data by the measured time for setting up the preconditioner. First for a blocksize of 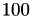 :
:
and also for a blocksize of 500:
The relatively large increase in the setup time is due to ℋ-inversion for the diagonal blocks, as performed by the TJacobi class. For small blocks, this is comparable to dense inversion, which is very fast for small matrices. However, depending on the ℋ-block structure, a more than linear increase may be visible for larger blocks (before ℋ-complexity is dominant).
TJacobi also accepts a fourth argument defining the accuracy of the ℋ-inversion, which defaults to exact inversion (up to machine precision):
In this example however, a relaxed accuracy only leads to very little change in the setup and solve times.
This is a typicall example that a more advanced preconditioner does not necessarily results in an overall performance increase. Only if the reduction in iteration steps is large enough to actually compensate the increase in the more costly setup phase, will the overall time also be reduced.
Gauss-Seidel Preconditioner
In addition to the diagonal of , the Gauss-Seidel preconditioner also uses the lower (forward GS), upper (backward GS) or both (symmetric GS) triangular part(s) of the matrix. This gives as the following preconditioners with  and
and 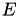 being the strict (block) lower triangular part of and
being the strict (block) lower triangular part of and 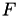 the strict upper triangular part respectively:
the strict upper triangular part respectively:
- Forward-GS:
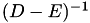 ,
, - Backward-GS:
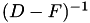 ,
, - Symmetric-GS:
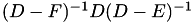 .
.
Let us test all three versions of Gauss-Seidel for the Helmholtz model problem.
Forward-GS:
Backward-GS:
Symmetric-GS:
Only Symmetric-GS shows a significant improvement over block-wise Jacobi in terms of convergence rates, with less that 100 iteration steps to solve the Helmholtz problem.
However, the solve time is significantly higher compared to Jacobi which is the result of the matrix solve algorithm in 𝖧𝖫𝖨𝖡𝗉𝗋𝗈. For one, solving a lower/upper triangular ℋ-matrix takes much longer than matrix-vector multiplication with a block-diagonal matrix since much more data is involved. Furthermore this matrix solve algorithm does not scale as efficiently with the number of CPUs as does matrix-vector multiplication, especially for a block-diagonal matrix.
- Remarks
- 𝖧𝖫𝖨𝖡𝗉𝗋𝗈 does not support block-GS with a larger block size than , which possibly would further improve convergence rates albeit with higher setup costs comparable to block-Jacobi.
ℋ-LU Preconditioner
Already Block-Jacobi and Gauss-Seidel made use of the block structure of ℋ-matrices and the correponding ℋ-arithmetic. Especially Block-Jacobi used ℋ-matrix inversion for the diagonal blocks.
Using ℋ-LU factorisation, a better approximation to can be computed by using the whole matrix instead of just the (block-) diagonal, which then in theory should serve as an excellent preconditioner. In fact, an exact (up to machine precision) computation of would result in a direct solver, i.e., only a single matrix-vector multiplication (or matrix-vector solve) would be needed for solving the equation system.
ℋ-arithmetic allows us to control the accuracy of the approximation, which thereby permits us to optimize the overall solution process, e.g., invest more time into setup (high accuracy ℋ-LU) or more time in the iteration process (low accuracy ℋ-LU) depending on our problem to solve.
For the Helmholtz problem, we will increase the block-wise ℋ-arithmetic accuracy 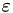 from
from 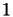 to .
to .
Except for the accuracy setting, the source for all examples is:
- Remarks
- Note, that already the copy of is constructed with a reduced accuracy, thereby starting with less data for ℋ-LU.
The numerical results are:
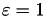
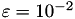
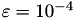
As expected, with a better ℋ-accuracy, the convergence rate also becomes better, until only two iteration steps are needed for . However, the setup time for computing the ℋ-LU preconditioner also increases significantly with a smaller , already passing matrix construction time for .
Regarding overall solve time: already ℋ-LU with the coarsest accuracy needs longer than a simple block-Jacobi preconditioner. Furthermore, matrix-vector solves as are needed for the application of ℋ-LU as a preconditioner are expensive, which already was a problem for Gauss-Seidel preconditioners.
All together, the advantage of ℋ-LU for this specific example will only show for many right-hand sides to solve. As an example, we compare TFQMR+Block-Jacobi (blocksize 100) with Linear Iteration+ℋ-LU ( ). Both solvers would need the same overall time for five right-hand side vectors (110.47s vs. 110.73s). Only for more vectors ℋ-LU shows a better performance than Block-Jacobi.
- Attention
- Again, this is only valid for this example matrix. Already for a larger problem size for the same Helmholtz example, the Jacobi preconditioner will need more iteration steps, which will shift the break-even point in favour of ℋ-LU.
Block-Diagonal ℋ-LU Preconditioner
The main problem with block-wise Jacobi for large block sizes was the large setup costs due to inversion of the diagonal matrix blocks. Instead of inversion, these blocks may also be factorised using ℋ-LU factorisation. This permits larger block sizes for block-Jacobi.
𝖧𝖫𝖨𝖡𝗉𝗋𝗈 provides two functions to either restrict a given matrix to it's block-diagonal part
or to copy the block-diagonal of a matrix:
In both cases, the block-diagonal is either defined by the level of the diagonal blocks or by their sizes, e.g., stop recursion if a certain level or a certain blocksize was reached. The default value lvl_leaf signals, that recursion should only be stopped at leaf level (or blocksize = ).
For our problem, a corresponding preconditioner is obtained via
The results for different block sizes are:
blocksize
blocksize 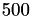
blocksize 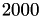
blocksize 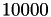
blocksize 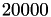
The results for a blocksize of and are (almost) identical to the block-Jacobi preconditioner above, only the setup time is reduced, e.g., from 5.19 seconds to 0.58 seconds for blocksize . The solve times are slightly worse than in the Jacobi version, since matrix-vector solves are involved.
However, already for a blocksize of , the overall time is faster and even better for a blocksize of with a minimum for . Although a larger block size will result in a better convergence but the setup time also increases making block-diagonal ℋ-LU to the fastest solver for our example in terms of overall time.
We have not discussed the accuracy used for ℋ-LU in case of block diagonal preconditioning. For the above tests, the accuracy was , i.e., a very coarse approximation. Tests with higher accuracy did not resulted in an improvment, for one because the block diagonal structure already sets a lower limit on the approximability of (see block-Jacobi) and second, because the setup time will then be higher. Only for very large block sizes, this could improve convergence but not necessarily solve times.
Nearfield ℋ-LU Preconditioner
Another alternative for computing a ℋ-based preconditioner is to restrict the matrix to the nearfield part only, as defined by the dense matrix blocks. All other low-rank blocks are considered to be zero and will not be updated during LU factorization. This algorithm can be considered as an incomplete LU with limited fill-in.
- Remarks
- If started with a sparse matrix, this method corresponds to an incomplete LU, where the fill-in is restricted to those matrix coefficients defined by the dense matrix blocks.
Since only dense arithmetic is involved, all computations are performed exact w.r.t. machine precision. Furthermore, the computation time is much faster compared to standard ℋ-LU. However, the approximation of is also limited.
As for block diagonal matrices, we have the following two functions to either restrict a given matrix or to copy the nearfield part:
The second parameter defines, whether low-rank blocks should be deleted/not copied or just zeroed.
In our case, this looks as:
And the results are:
The solve times are not as fast as in the case with block diagonal (Jacobi or ℋ-LU), but not much worse. Especially the fast setup makes this version interesting. Also matrix-vector solves are faster than for standard ℋ-LU.
Conclusion
For the given Helmholtz problem with a single right-hand side, the fastest solver of the block-diagonal ℋ-LU factorisation with a block size of . The reason was the fast factorisation of the diagonal blocks, i.e., a low setup time, with a reasonable number of iteration steps.
Using the standard ℋ-LU preconditioner with for comparsion (ℋ-LU time is similar to matrix construction time), it needs 6 right-hand side vectors to be faster than block-diagonal ℋ-LU.
- Attention
- To emphasize again: the results are for a specific problem. What is not visible in the data is for instance the dependency of the number of iteration steps on the problem dimension which is typical for classical precondtioners like Jacobi or Gauss-Seidel. Furthermore, convergence rates are strongly dependent on the properties of a matrix (we leave out convergence theory here).
